
What is A21 Labs Jamba?
Breaking News, hot off the press. ⚗️


Hey Everyone,
For anyone that knows me, I’m a huge fan of Labs that get less credit like Aleph Alpha in Germany and A21 Labs in Israel.
This will just be a short piece on Jamba.
Introducing Jamba: AI21's Groundbreaking SSM-Transformer Model
Tracking open-source model innovation has become more challenging. Since each week there are now several releases.

So in a nutshell, here is what we have:
Let’s see this a little bigger in case you are reading this on a web-browser:

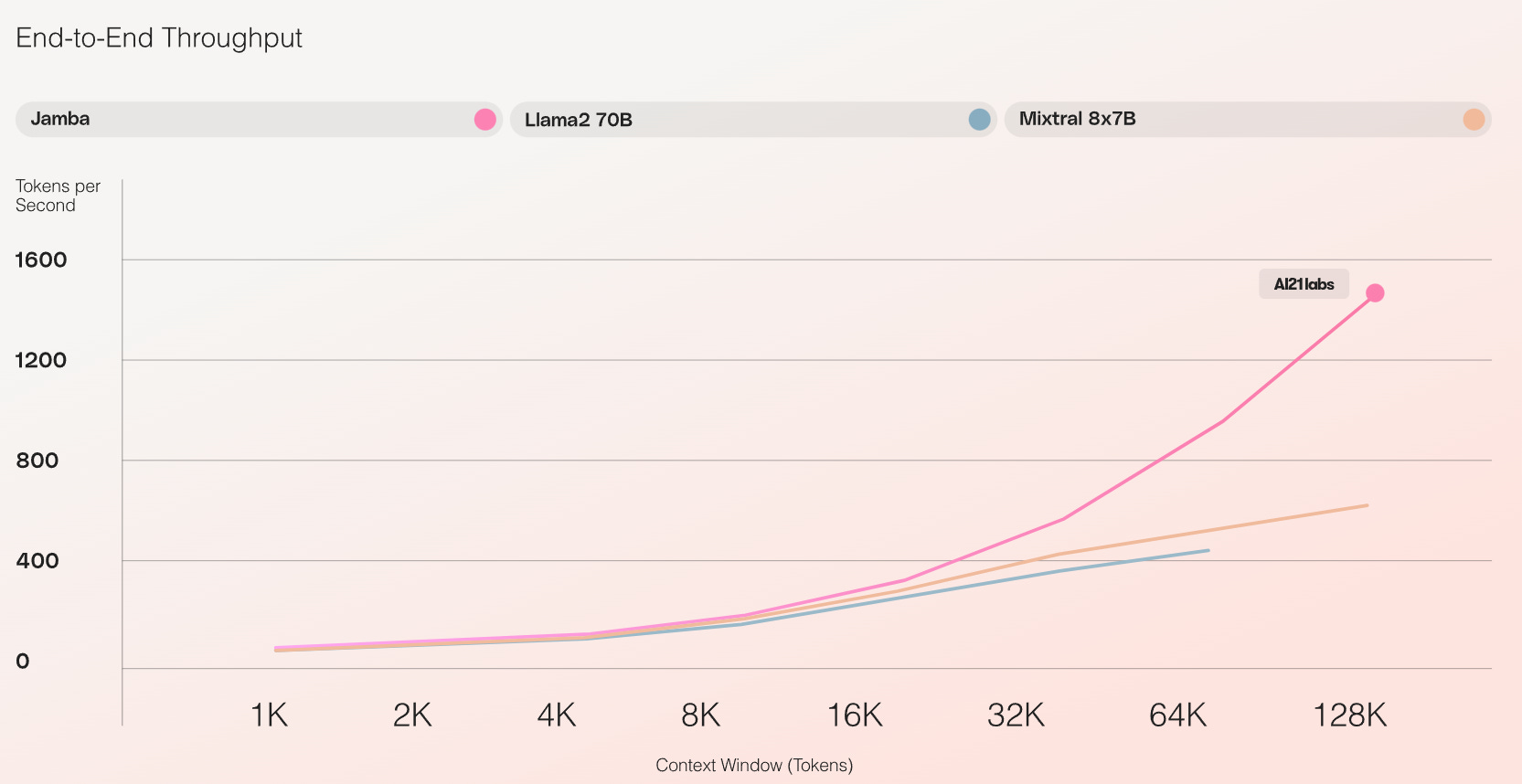
Offering a 256K context window, it is already demonstrating remarkable gains in throughput and efficiency—just the beginning of what can be possible with this innovative hybrid architecture. Notably, Jamba outperforms or matches other state-of-the-art models in its size class on a wide range of benchmarks.
TL;DR
🧠 52B parameters with 12B active during generation
👨🏫 16 experts with 2 active in generation
🆕 New architecture with Joint Attention and Mamba
⚡️ Supports 256K context length
💻 Fits up to 140K context on a single A100 80GB
🚀 3X throughput on long contexts compared to Mixtral 8x7B
🔓 Released under Apache 2.0
🤗 Available on Hugging Face & Transformers (>4.38.2)
🏆 Rivals open LLMs on Open LLM Leaderboard Benchmarks
❌ No information about training data or language support
Model: https://huggingface.co/ai21labs/Jamba-v0.1
This is how A21 Labs introduced the new model on LinkedIn.
Open-Source
In releasing Jamba with open weights, licensed under Apache 2.0, we invite further discoveries and optimizations that build off this exciting advancement in model architecture. We can’t wait to see what you’ll build.
Open-Source Models are Increasing Context Length

For A21 Labs, it’s a coming out party of sorts. As the first production-grade model based on Mamba architecture, Jamba achieves an unprecedented 3X throughput and fits 140K context on a single GPU.
Jamba on Nvidia NIM
Jamba will also be accessible from the NVIDIA API catalog as NVIDIA NIM inference microservice, which enterprise applications developers can deploy with the NVIDIA AI Enterprise software platform.
Key Features
First production-grade Mamba based model built on a novel SSM-Transformer hybrid architecture
3X throughput on long contexts compared to Mixtral 8x7B
Democratizes access to a massive 256K context window
The only model in its size class that fits up to 140K context on a single GPU
Released with open weights under Apache 2.0
Available on Hugging Face and coming soon to the NVIDIA API catalog
A21 Labs competes Favorably with Mistral
“To capture the best that both Mamba and Transformer architectures have to offer, we developed the corresponding Joint Attention and Mamba (Jamba) architecture. Composed of Transformer, Mamba, and mixture-of-experts (MoE) layers, Jamba optimizes for memory, throughput, and performance—all at once.”
We are seeing more MoE’s with 16 experts - Jamba’s MoE layers allow it to draw on just 12B of its available 52B parameters at inference, and its hybrid structure renders those 12B active parameters more efficient than a Transformer-only model of equivalent size.
AI12’s First Open-Sourced Model Looks Impressive
AI21’s first open-sourced model marks a significant milestone in GenAI innovation, debuting the first production-grade Mamba-based model delivering best-in-class quality and performance.
Jamba achieves an unprecedented 3X throughput on long contexts, and it is the only model of its size that fits 140K context on a single GPU. Jamba offers exceptional efficiency and scalability, empowering developers and businesses to power critical use cases in the most reliable and cost-effective way.
AI21’s Jamba architecture

First production-grade Mamba based model built on a novel SSM-Transformer hybrid architecture
3X throughput on long context compared to Mixtral 8x7B
Democratizes access to a massive 256K context window
The only model in its size class that fits up to 140K context on a single GPU
Released with open weights under Apache 2.0
Available on Hugging Face and coming soon to the NVIDIA API catalog
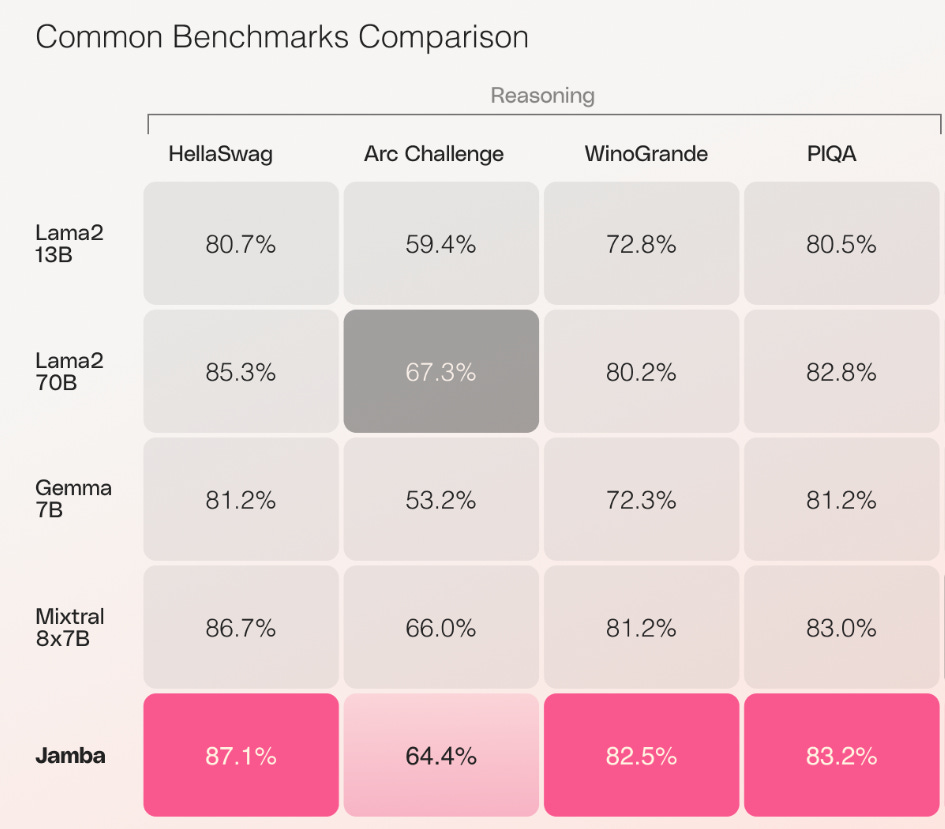
Advanced Reasoning Performance
What does Jamba stand for?
Jamba is an acronym that stands for Joint Attention and Mamba (Jamba) architecture, and it aims to bring the best attributes of SSM and transformers together.