


Moonshot AI just released Kimi K2
China is not so behind in Agentic AI either it would seem.

With Grok 4 and Windsurf going to Google and not OpenAI, many people missed another major model launch by a Chinese AI startup. Moonshot AI is one of the “Four Tigers” of China’s AI startup squad.
“China just dropped the best open source AI model for coding and agentic tool use.
Kimi K2 scores an insane 65.8% on SWE-Bench Verified. As cheap as Gemini Flash at only $0.6/M input, $2.5/M out.
It oneshots this data analysis task in Python and creates a website for a few cents.”
Kimi K2 is an important Agentic AI model.

Try Kimi K2 on kimi.com
Highlights
1T total / 32B active MoE model
SOTA on SWE Bench Verified, Tau2 & AceBench among open models
Strong in coding and agentic tasks
Follow them on X. They are working on the Paper for Kimi K2.
Kimi K2: Open Agentic Intelligence
Kimi K2 is Moonshot AI’s latest Mixture-of-Experts model with 32 billion activated parameters and 1 trillion total parameters.
It achieves state-of-the-art performance in frontier knowledge, math, and coding among non-thinking models. But it goes further — meticulously optimized for agentic tasks, Kimi K2 does not just answer; it acts.
And now, it is within your reach. Check out demo video.
Kimi-K2-Base: The foundation model, a strong start for researchers and builders who want full control for fine-tuning and custom solutions.
Kimi-K2-Instruct: The post-trained model best for drop-in, general-purpose chat and agentic experiences. It is a reflex-grade model without long thinking.
With Kimi K2, advanced agentic intelligence is more open and accessible than ever. We can't wait to see what you build.
Let’s go into a bit more detail: Kimi K2 comes in two variants, each tailored to different use cases:
Kimi-K2-Base: This is the foundational model, designed for researchers and developers who want to fine-tune or customize the model for specific applications. It provides raw capabilities that can be adapted for specialized domains, such as scientific research, legal analysis, or custom chatbot development.
Kimi-K2-Instruct: This is the instruction-tuned version, optimized for general-purpose conversational tasks and agentic workflows. It’s pre-configured to follow user instructions accurately, making it ideal for immediate deployment in chat-based applications or as an AI assistant for tasks like coding, writing, or problem-solving.
“On standard LLM benchmarks, Kimi-K2-Instruct—the version optimized for real-world use—lands in the same league as leading closed models.”
Benchmarks and Performance
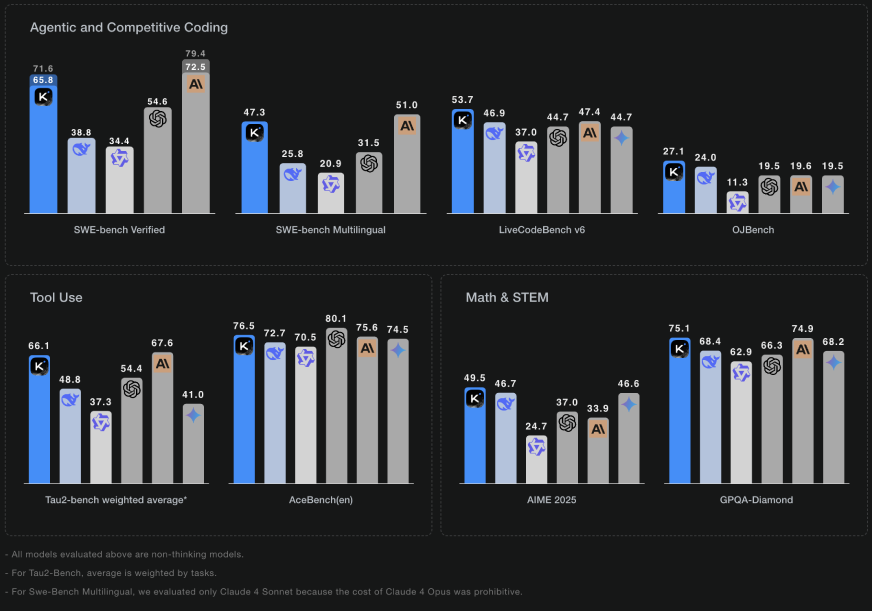
So why are people noticing this?
Kimi K2 delivers state-of-the-art and open-source leading results in the following benchmarks:
SWE-bench Verified: 65.8% single-attempt accuracy
SWE-bench Multilingual: 47.3% (best among tested models)
LiveCodeBench v6: 53.7%
OJBench: 27.1%
Tau2-bench (weighted average): 66.1%
AceBench (en): 80.1%
AIME 2025: 49.5%
GPQA-Diamond: 75.1%
So - On SWE-bench Verified, it scores 65.8 percent in agent mode, just behind Claude Sonnet 4 and well ahead of GPT-4.1 (54.6 percent). That’s stunning for an open-weight model.
Kimi-K2 also leads the pack on LiveCodeBench (53.7 percent) and OJBench (27.1 percent) without a reasoning module. These tests measure how well language models tackle programming problems—LiveCodeBench interactively, OJBench as traditional competition tasks, as per The Decoder.
While MiniMax and Zhipu AI have made a lot of progress, Baichuan hasn’t faired so well and Manus pivoting to Singapore is a bit odd.
Moonshot AI has flown a bit more under the radar.

“The model’s standout feature is its optimization for “agentic” capabilities — the ability to autonomously use tools, write and execute code, and complete complex multi-step tasks without human intervention.”
Kimi K2 read 15.5 trillion tokens, basically the internet many times over. It tries to guess the next word, checks if it was right, and improves over time. The more it reads, the better it gets.

Agentic Capabilities
The enhanced agentic capabilities of Kimi K2 originate from two important aspects — large-scale agentic data synthesis and general reinforcement learning.


All to say that Chinese AI startups are impacting the evolution of how Agents are moving from the lab into the real world and application layer products.
Try Kimi K2 on kimi.com
Their blog and Github is also incredibly transparent in the spirit of DeepSeek. So China’s Open-source approach to sharing their research and evolution has a new vibe.
Near SOTA in Agentic Coding

SOTA in Tool Use for Agents

Model Summary
Kimi K2 is a state-of-the-art mixture-of-experts (MoE) language model with 32 billion activated parameters and 1 trillion total parameters. Trained with the Muon optimizer, Kimi K2 achieves exceptional performance across frontier knowledge, reasoning, and coding tasks while being meticulously optimized for agentic capabilities.
The crazy part? Kimi K2-Instruct doesn’t just compete with the big players — it systematically outperforms them on tasks that matter most to enterprise customers.
Key Features
Large-Scale Training: Pre-trained a 1T parameter MoE model on 15.5T tokens with zero training instability.
MuonClip Optimizer: We apply the Muon optimizer to an unprecedented scale, and develop novel optimization techniques to resolve instabilities while scaling up.
Agentic Intelligence: Specifically designed for tool use, reasoning, and autonomous problem-solving.
Their API

- $0.15 / million input tokens (cache hit)
- $0.60 / million input tokens (cache miss)
- $2.50 / million output tokens
Chinese energy and cost advantage appears very real as we head into agentic AI products and applications. While OpenAI burns through hundreds of millions on compute for incremental improvements, Moonshot appears to have found a more efficient path to the same destination.
A lot of people aren’t realizing Moonshot AI also this summer announced a very interesting project.
What is Kimi-Researcher?
Moonshot AI also make Kimi-Researcher - an autonomous agent that excels at multi-turn search and reasoning. Powered by k 1.5 and trained with end-to-end agentic RL. Achieved 26.9% pass@1 on Humanity's Last Exam, 69% pass@1 on xbench.

Kimi-Researcher is an autonomous agent that excels at multi-turn search and reasoning. It performs an average of 23 reasoning steps and explores over 200 URLs per task.
Addendum Hot Takes
Bijan Bowen
Wes Roth
WordofAI
AI Revolution
A Model that is a Pragmatic Doer? 👀
Kimi K2 moves from reasoning to action. It doesn’t just respond—it executes. The core shift lies in enabling real-world workflows:
Autonomous code execution
Data analysis with charts and interfaces
End-to-end web application development
Orchestration of 17+ tools per session without human input
Benchmarks Continued:
Look at the below carefully:

Design, Architecture and Training Innovation
K2’s technical design demonstrates several novel elements:
MoE Transformer Design: 384 experts with routing to 8 active experts per token, plus 1 shared expert for global context. The model uses 64 attention heads and supports a 128K-token context window.
MuonClip Optimizer: A modified version of Muon that stabilizes training at scale. It uses qk-clipping to constrain attention scores by rescaling Q/K matrices, effectively preventing instability in deep layers.
Training Dataset: Over 15.5 trillion tokens from multilingual and multimodal sources, giving K2 robust generalization and tool-use reasoning across diverse domains.
The MuonClip Optimizer Advantage 🌙
The MuonClip Optimizer is a specialized optimization technique developed by Moonshot AI for training their Kimi K2 model, a state-of-the-art mixture-of-experts (MoE) language model with 1 trillion total parameters and 32 billion activated parameters. It is an advanced variant of the Muon optimizer, designed to address the challenge of training instability in large-scale language models, particularly those with massive parameter counts.
Efficiency Gains:
By addressing instability at the source (attention logits), MuonClip reduces computational overhead, potentially lowering the cost of training large models. This could provide a competitive advantage in an industry where training runs cost tens of millions of dollars.
Previous optimizers like AdamW and the original Muon optimizer either lacked efficiency or suffered from instability at this scale. This has neither of those issues.

Super Pricing? 🛒
At $0.15 per million input tokens for cache hits and $2.50 per million output tokens, Moonshot is pricing aggressively below OpenAI and Anthropic while offering comparable — and in some cases superior — performance.
Coding Tasks
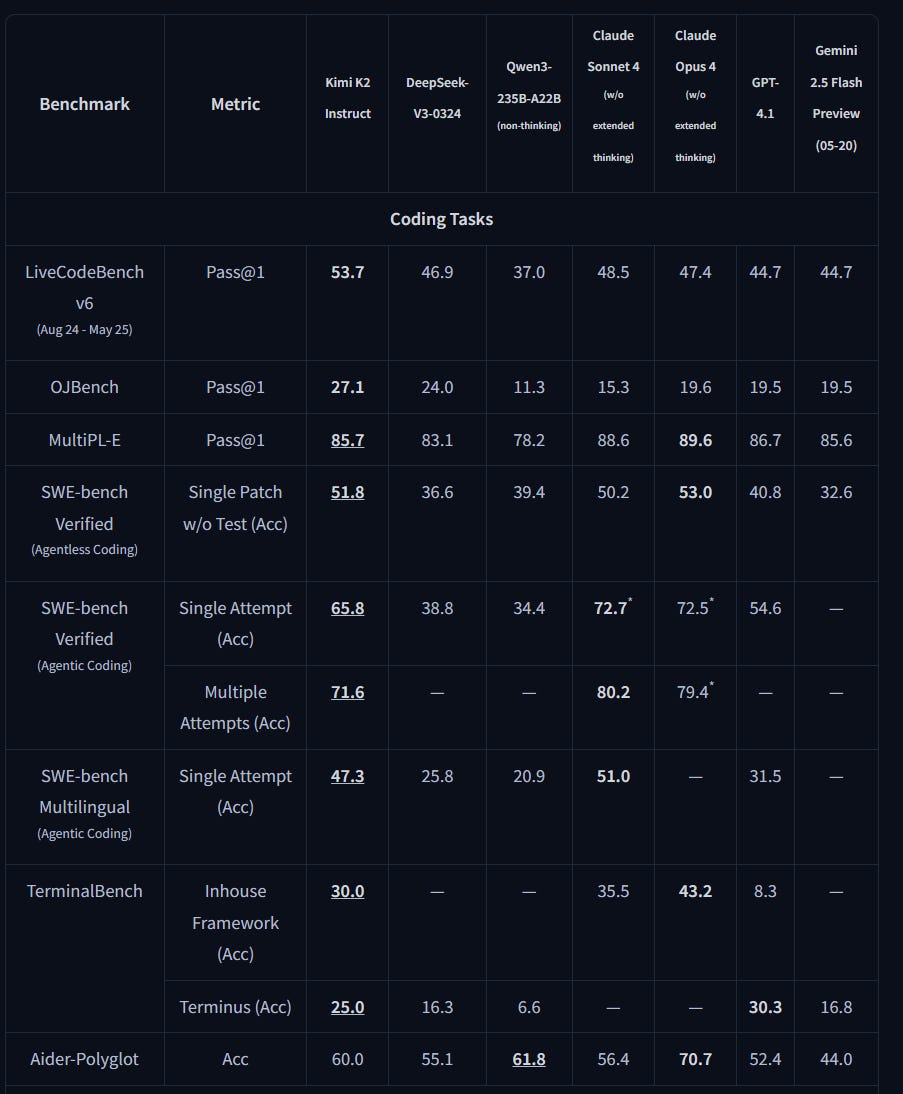
It’s nearly a peer to Claude 4 and better in some areas.
Tool Use

Relative parity with Claude 4 models
Math and STEM Tasks

Substantially better than most peers in Math, Science, Technology and Engineering related tasks.
General Tasks
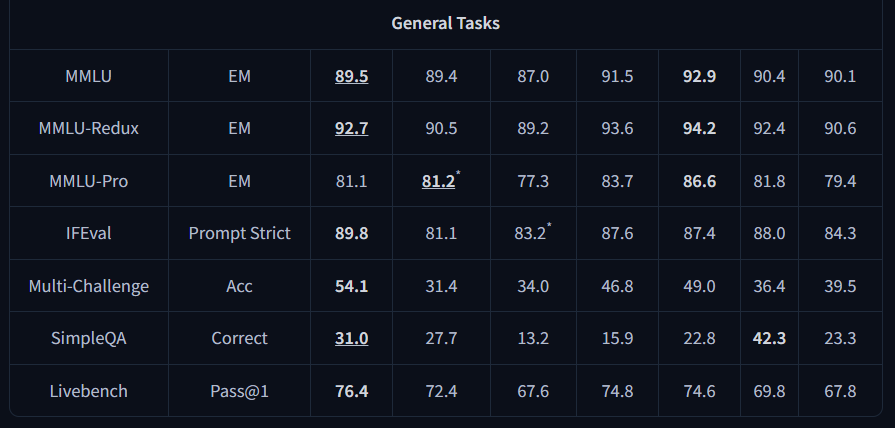
A peer to most Closed source models in general tasks.
“Kimi K2 is basically DeepSeek V3 but with fewer heads and more experts” -

So how can an open-source cheaper model with a permissive license achieve parity with Closed model LLMs of the West?
The implication and trends are clear—Kimi K2’s performance as an open model signals not just technological acceleration but a shifting terrain for labor, cognition, and value.
https://sonderuncertainly.substack.com/p/its-climate-change-for-your-job
It appears DeepSeek's approach and ideology has had an impact on China's national policy around generative AI. Not everything needs to show up on the stock market to matter. China's approach to proliferating models at a low cost will be difficult to combat.