
Qwen3-Coder: New release - Qwen3-Coder-480B-A35B-Instruct
Alibaba is becoming a force to be reckoned with in the democratization of AI. Especially in mainland China and sympathetic neighbours.

! 🤯")
This breaking news out of Alibaba Qwen is getting a bit ridiculous. I think the west continues to underestimate BAT companies out of China (Baidu, Alibaba, Tencent). But how dominant is Alibaba becoming in open-weight LLMs?
Qwen, also known as Tongyi Qianwen (Chinese: 通义千问), is a family of large language models (LLMs) and multimodal models developed by Alibaba Cloud, the cloud computing division of Alibaba Group, a major Chinese technology company.
Their latest model is the much awaited Qwen3-Coder. It’s important for the future of how China wins in agentic AI and application layer products that can actually do things.
TL;DR
Qwen releases Qwen3-Coder, a SOTA coding model that rivals Claude Sonnet-4, GPT-4.1 & Kimi K2. ⭐

Launched in beta in April 2023 and publicly released in September 2023 after Chinese government approval, Qwen is designed to compete with leading AI models like ChatGPT, Gemini, and DeepSeek AI. But moreover, unite the best research around open-weight (open-source) LLMs to bring China’s ecosystem of LLM maker and product builders frontier level performance.
That is starting to actually become the case in 2025. Alibaba has invested in many of the top bleeding edge research labs around LLMs. This has given them an inside track where even Meta AI could no longer compete has pivoted to closed-source with their Meta Superintelligence Lab project.
Alibaba is winning, not just in the Cloud in Asia. You can directly access the API of Qwen3-Coder through Alibaba Cloud Model Studio.
In Case you Missed It
Recently I’ve had been trying to track some of China’s big announcements:
Both of these events make July, 2025 an exceptional month where August should bring us DeepSeek-R2 and GPT-5 in all likelihood.
Qwen 3 is SOTA in Coding and Agentic AI in Open-weight LLMs
Qwen3-Coder is available in multiple sizes, but we’re excited to introduce its most powerful variant first: Qwen3-Coder-480B-A35B-Instruct — a 480B-parameter Mixture-of-Experts model with 35B active parameters which supports the context length of 256K tokens natively and 1M tokens with extrapolation methods, offering exceptional performance in both coding and agentic tasks.
Qwen3-Coder-480B-A35B-Instruct sets new state-of-the-art results among open models on Agentic Coding, Agentic Browser-Use, and Agentic Tool-Use, comparable to Claude Sonnet 4.

The open-weight ecosystem of China is so under-reported in journalism, media and Newsletters in the West, it’s very bizarre. Even AI researchers in the open-source field typically don’t go into much detail.
What is Qwen3-Coder?
Quote from the blog: “Alongside the model, we’re also open-sourcing a command-line tool for agentic coding: Qwen Code. Forked from Gemini Code, Qwen Code has been adapted with customized prompts and function calling protocols to fully unleash the capabilities of Qwen3-Coder on agentic coding tasks. Qwen3-Coder works seamlessly with the community’s best developer tools. As a foundation model, we hope it can be used anywhere across the digital world — Agentic Coding in the World!”
Qwen3-Coder Specs
Pre-Training
There’s still room to scale in pretraining—and with Qwen3-Coder, we’re advancing along multiple dimensions to strengthen the model’s core capabilities:
Scaling Tokens: 7.5T tokens (70% code ratio), excelling in coding while preserving general and math abilities.
Scaling Context: Natively supports 256K context and can be extended up to 1M with YaRN, optimized for repo-scale and dynamic data (e.g., Pull Requests) to empower Agentic Coding.
Scaling Synthetic Data: Leveraged Qwen2.5-Coder to clean and rewrite noisy data, significantly improving overall data quality.

Key Features
Model Size: 480 billion parameters (Mixture-of-Experts), with 35 billion active parameters during inference.
Architecture: 160 experts, 8 activated per inference, enabling both efficiency and scalability.
Layers: 62
Attention Heads (GQA): 96 (Q), 8 (KV)
Context Length: Natively supports 256,000 tokens; scales to 1,000,000 tokens using context extrapolation techniques.
Supported Languages: Supports a large variety of programming and markup languages including Python, JavaScript, Java, C++, Go, Rust, and many more.
Model Type: Causal Language Model, available in both base and instruct variants.
China Stretches Ahead in the Democratization of Agentic Coding Tasks
Qwen3-Coder was introduced on July 22, 2025, with the flagship model Qwen3-Coder-480B-A35B-Instruct, a 480B-parameter Mixture-of-Experts model with 35B active parameters, excelling in agentic coding tasks.
Chat: https://chat.qwen.ai
Blog: https://qwenlm.github.io/blog/qwen3-coder/
Model: https://hf.co/Qwen/Qwen3-Coder-480B-A35B-Instruct
Qwen Code: https://github.com/QwenLM/qwen-code
Qwen 3’s furious releases of late are just before GPT-5 and DeepSeek-R2 come out and position Qwen as a trail-blazer in the open-weight LLM space. As they dig their heels into Agentic AI it could transform China’s ability to compete on the application and product layer in a more actionable Generative AI ecosystem globally.
Few realize or give credit that this becoming Alibaba’s strength. China’s democratic open-weight principles are the real legacy of China’s DeepSeek moment in early 2025.
The efficiency levels Qwen and DeepSeek are able to produce both in RL, hardware and software is remarkable. China’s lack of decent AI chips might actually have been a mixed blessing. U.S. export controls and policy did this to themselves. This is what happens when you don’t compete or attempt to suppress your rivals. It forces them to actually innovate.
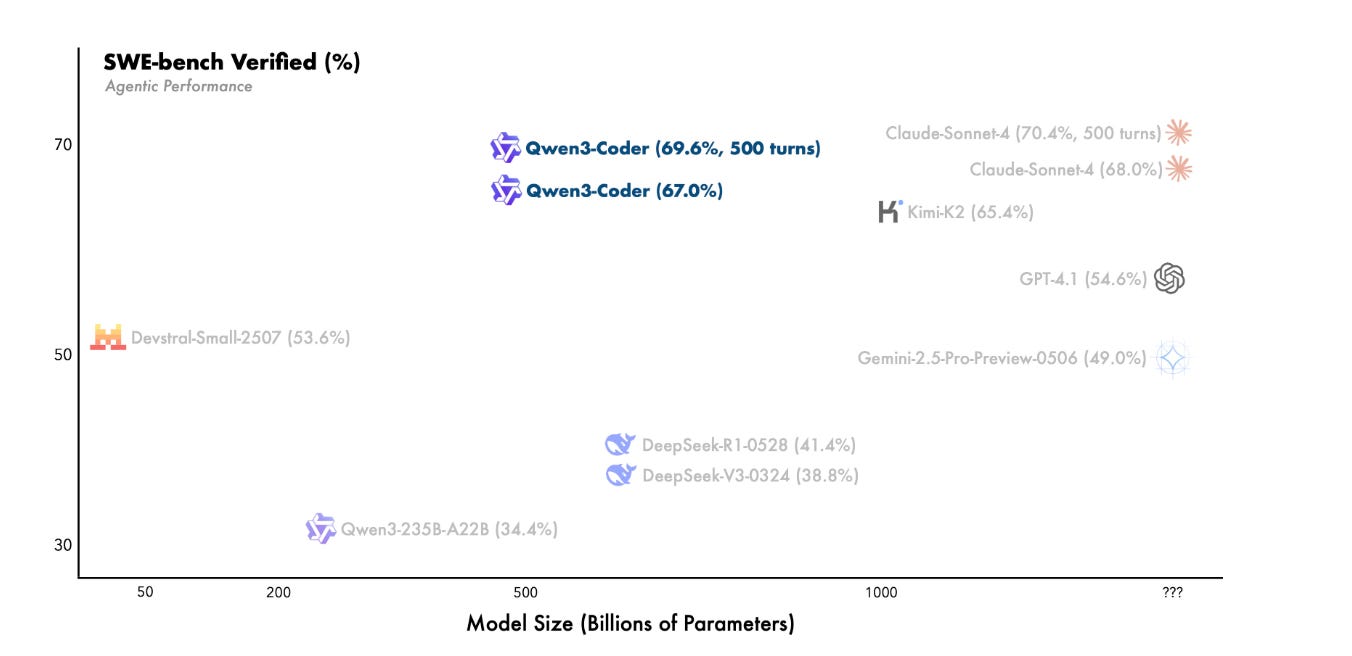
Qwen 3’s Agentic Capabilities approaching Real-World Level Capabilities
In real-world software engineering tasks like SWE-Bench, Qwen3-Coder must engage in multi-turn interaction with the environment, involving planning, using tools, receiving feedback, and making decisions. In the post-training phase of Qwen3-Coder, we introduced long-horizon RL (Agent RL) to encourage the model to solve real-world tasks through multi-turn interactions using tools. The key challenge of Agent RL lies in environment scaling. To address this, we built a scalable system capable of running 20,000 independent environments in parallel, leveraging Alibaba Cloud’s infrastructure. The infrastructure provides the necessary feedback for large-scale reinforcement learning and supports evaluation at scale. As a result, Qwen3-Coder achieves state-of-the-art performance among open-source models on SWE-Bench Verified without test-time scaling.
By around 2027 I believe this is going to evolve into something fairly special. The foundations are there.

Benchmarks Overview
Benchmarks
SWE-bench-Verified: Achieves state-of-the-art results among open models on this challenging real-world coding task suite, outperforming or matching proprietary closed models in performance.
Additional Agentic Tasks: Excels at Agentic Coding, Agentic Browser-Use, and Agentic Tool-Use, comparable to top-tier models such as Claude Sonnet-4.
Breadth: Demonstrates high proficiency across competitive programming, automated testing, code refactoring, and debugging.
The agnostic aura of DeepSeek, Qwen and others from China is in stark contrast to the people-pleasing interfaces of OpenAI and even Claude. Sometimes you just want capabilities without the gimmicks and retention gamification features.
Feel free to try out the API of Qwen3-Coder on Alibaba Cloud Model Studio!
Qwen’s variety of models to suite the needs of SMBs and businesses is growing, in both flexibility and capability. Mistral or others in the West do not achieve parity.
Key Features
Origin: Forked from Gemini Code (gemini-cli), ensuring compliance and open-source accessibility.
Custom Prompts and Protocols: Enhanced with custom prompts and advanced function call protocols tailored for Qwen3-Coder, unlocking agentic use-cases such as tool integration, multi-turn code refinement, and context injection.
Developer Integration: Designed to work seamlessly with best-in-class community tools, editors, and CI systems. Supports dynamic code interactions, repository-scale tasks, and direct function calling.
Enhanced Tool Support: Utilizes an upgraded parser and function call logic to empower agentic workflows and program synthesis.
Future Directions
The Qwen researchers remark that they are still actively working to improve the performance of our Coding Agent, aiming for it to take on more complex and tedious tasks in software engineering, thereby freeing up human productivity. More model sizes of Qwen3-Coder are on the way, delivering strong performance while reducing deployment costs. Additionally, we are actively exploring whether the Coding Agent can achieve self-improvement—an exciting and inspiring direction.
I urge you to carefully monitor Qwen and DeepSeek’s cost to performance ratio of their open-weight and accessible models.
I will update this post if more relevant information becomes available. For open-weight LLMs approaching agentic parity with the west, this is a huge move forwards for China.
In Case you Missed It
Recently I’ve had been trying to track some of China’s big announcements:
You can also run it with unlsoth:

Addendum Editor’s Notes
Qwen Code has elements of being “Forked from Gemini-CLI” which is Apache 2.0 so a fork is in keeping with the license.

As you can imagine, Simon also wrote about this.
It's also available as qwen3-coder on OpenRouter.
Alibaba Cloud itself also has some useful specs.
A good technical article on Qwen3-Coder can be found here.

APIdog tries to go into more depth with some added context.

The Big Picture
Qwen3-Coder
Achieves state-of-the-art results for open models in:
Agentic Coding
Agentic Browser-Use
Agentic Tool-Use
But due to its open-weight context, it will foster new application layer apps and Gen AI products, many of which will be made in China or by Chinese builders. Including Chinese led teams based in the U.S.
According to the release, Qwen3-Coder outperformed domestic competitors, including models from DeepSeek and Moonshot AI's K2 in key coding capabilities. The big caveat is DeepSeek-R2 and its related models have yet to drop.